The last challenge left for me to solve, is the "Blocky" challenge from the Misc category.

This challenge comes with a ZIP-file. Firstly we inspect the downloaded file with file and get a confirmation on the zip-file format blocky.zip: Zip archive data, at least v2.0 to extract. With a quick unzip to deflate the file, we get a directory named blocky. This directory contains 251 files named and sized similar:
$ ls blocky | wc -l
251
$ ll blocky | head
total 15060
-rw-r--r-- 1 investigator01 investigator01 59780 Aug 30 2017 ACnAcLGpxKFQpvkh.txt
-rw-r--r-- 1 investigator01 investigator01 59780 Aug 30 2017 adnIltWBcbQqUtHn.txt
-rw-r--r-- 1 investigator01 investigator01 59780 Aug 30 2017 AOtzXFmlFYlgZuSe.txt
-rw-r--r-- 1 investigator01 investigator01 59780 Aug 30 2017 asVpMWRoxkVXPZpG.txt
-rw-r--r-- 1 investigator01 investigator01 59780 Aug 30 2017 auCSDCYRrUqbVuBb.txt
-rw-r--r-- 1 investigator01 investigator01 59780 Aug 30 2017 AYZVZxovyLLaGorA.txt
-rw-r--r-- 1 investigator01 investigator01 59780 Aug 30 2017 bCLevFNJoKpWWyAo.txt
-rw-r--r-- 1 investigator01 investigator01 59780 Aug 30 2017 BjDyzhVUTNxiGMAe.txt
-rw-r--r-- 1 investigator01 investigator01 59780 Aug 30 2017 BkHFBLEcHEvCxkDx.txtFurther enumeration on the files shows that they all are ASCII-text files:
$ file blocky/* | cut -d " " -f 2 | uniq -c
251 ASCIILooking at the content of the files, we see they contain 244 lines each with 244 numeric values of 1 or 0 - very much assembling some kind of "binary ASCII-art" divided in "blocks" - one per file. On every file, the binary 1's and 0's doesn't appear to be 100% correct binary - at least without any useable data, as they are grouped by four. Either 1's or 0's - often multiple groups together, but always dividable-by-four. A bit strange. From here I see two possible ways to go - follow the "binary-ascii-art" and further elaborate what that might contain, or try to decode the binary to hex for all the files seeing if the few files I opened just was to "obfuscate by the sheer number of files and data".
The filenames might as well be interesting as they are all alphanumeric without the 10 arabic numerals, and always 16 chars long. It could almost look like some sort of base64 or similar, but further investigating in that direction - both single filenames, and combined, gave not usable results. It could also be some kind of key to different encode-types further on.
After some considerations and investigations, I tried providing one of the files to https://onlinebinarytools.com/convert-binary-to-image. This immediately gave off that the files really was a kind of QR-code. The file I was testing with ACnAcLGpxKFQpvkh.txt didn't seem to catch anything when I tried to scan it -- but the generated "qr-image" was "long" and not very easy for a camera to catch. Maybe one was much better than the rest?
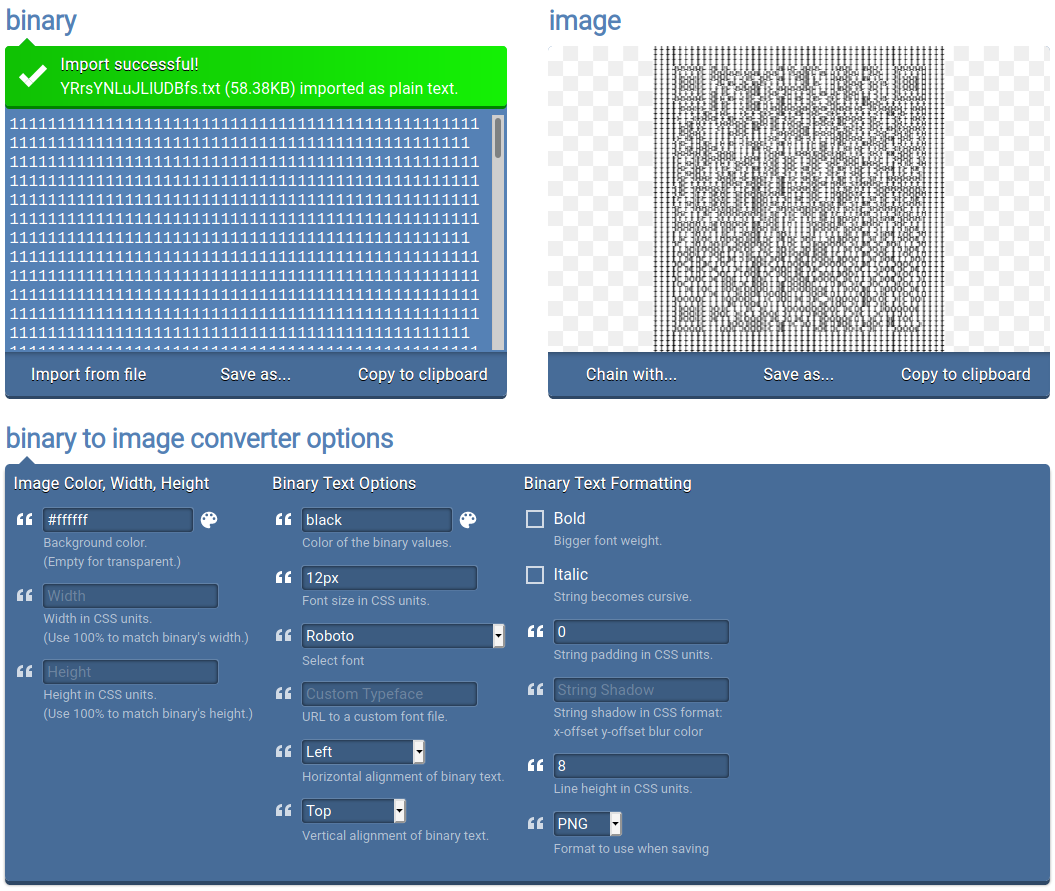
Let's see if any of the 251 files is significant different from the others.
Lets try with some checksum'ing:
$ sha256sum blocky/*
6d68a4b9aa1565513eec6f68b032198a290fa28f401f6762144b12db39d0b7f9 blocky/ACnAcLGpxKFQpvkh.txt
7a376566e8f3e4a11800b8e287f8c230cf239303f914c8b0a6e85d3d638f8bf6 blocky/adnIltWBcbQqUtHn.txt
002566d2762d69a13af56a4d192fee9d7e431393286b1de68bb8082fc15b2fac blocky/AOtzXFmlFYlgZuSe.txt
a8334f2c90bb7b1b87535751a43230dbdfb0ed7fcdf4ef15c12e15a602a2caa7 blocky/asVpMWRoxkVXPZpG.txt
b34e752c8ec9f48613d5c10fd759ce663306faad8ed03d26b107e59f7c2f27c4 blocky/auCSDCYRrUqbVuBb.txt
d0c9dce4227681ffe5470d71fe09fe7ea96cd88a096fb85e0a3563bb9823fdc0 blocky/AYZVZxovyLLaGorA.txt
f0893cc048c400945f644dab432a47a015c9f17463469e8e3c951a1c3e3c8604 blocky/bCLevFNJoKpWWyAo.txt
00dec7ad7f59ae63ac53758160b5fe4ac2c5a109853b5bfd5c893cefbe4f6619 blocky/BjDyzhVUTNxiGMAe.txt
7d806e3879ab41ce17aab464571d38f59107a8c83729f713445702f6d6e71623 blocky/BkHFBLEcHEvCxkDx.txt
72c47ed61d07c8596bbf6b556de2332559934c0ae00ab89c82a4f6c71999d7cd blocky/bqVFLrUunGGWuqyv.txt
68d8adef7a25d6c7ddfde7d8747a14d982edea252a087d76412472ecd3d6f75a blocky/brSEWDIhcDlLilSK.txt
72a2db3d2ff5f5f6a4e772fec1abd428841b9d4ee528d10ae3fc1c972ba6867b blocky/bTJqVnMSeMnZQRHX.txt
d91133207f6d535ce6c7e071227ed28687c9947767e5df0d6805f008938f8d70 blocky/bwtMyuwPagUCUbEI.txt
dadb7c6c76cb2f21c40df3b6f155555deb98f4bbf9a0f4faeb8cb99105e2efab blocky/BXcwUVjemPhqPOIX.txt
[...]Dang it - they all seems to be different. Some fiddling later with the convert-binary-to-image (setting font size to 12px, string padding to 0 and line height to 8) the produced image is able to be scanned when resized down.

For two random files this have given us the QR-code text-values of 7359686d42576b66704372724d6e6571634c4d48634d694f51664e7959634c63647953724c4e6f52456f62 and 5271567678626a4f6277677a715841796d66686d5647465152786f41645551684e49724979504d4c626549. Further looking on those, converting from HEX and thereafter base64, it seems to be a dead-end. Somehow I think we need to "work-the-system" to figure out which one of the 251 files is the correct QR-code to continue working with.
To do this, we need to process all the 251 files into QR-code images and then scan them all - a task screaming for some happy-coding in my language of choice; Python.
With the code below, I've managed to create 251 images containing really pretty QR-codes, all saved in the folder ./images/. The code really is quite simple - for every file, create an image-file, interpret each 244 file-lines as a "scan-line" in the image (just like CRT-monitors) each containing 244 "pixels". For these "pixels" we paint a black pixel for every 0-character and a white pixel for every 1-character. And behold! We now have 251 QR-code images.
#!/usr/bin/env python3
import os
from PIL import Image
for raw_file in [f for f in os.listdir('./blocky/')]:
with open(f'./blocky/{raw_file}', 'r') as file:
data = file.readlines()
h = 244
w = 244
img = Image.new('RGB', (h, w))
y = 0
x = 0
item = 0
for y in range(0, h):
x = 0
try:
for char in data[item]:
if char == "0":
img.putpixel((x, y), (0, 0, 0)) # Place a black pixel for 0's
else:
img.putpixel((x, y), (255, 255, 255)) # Place a white pixel for 1's
x += 1
except IndexError as e:
pass
item +=1
y += 1
img.save(f'./images/{raw_file[:-4]}.png')
img.closeThe images produced by this code is far better than the direct online converting, as seen in the below image.

This was really step 1 of 2 in the QR-code steps - now we need to scan all the images to extract the codes within. We can do this with python again. See the code below. Using the opencv package to scan the image-files for QR-codes and then extract them, gives a long list that I saved as "qr_codes.txt" via python3 tinker2.py | tee qr_codes.txt.
A few of the images (around 10-ish) wouldn't give their codes to me - this might be that these have special meaning in the challenge and we might need to investigate that further. But looking at the images, they seemed just like the rest. So not to use too much time, I just scanned them manually via a phone and edited the file with the last codes.
#!/usr/bin/env python3
import os
import cv2 # pip3 install opencv-python
for raw_file in [f for f in os.listdir('./images/')]:
img = cv2.imread(f'./images/{raw_file}')
detector = cv2.QRCodeDetector()
data, vertices_array, binary_qrcode = detector.detectAndDecode(img)
if vertices_array is not None:
print(f'{raw_file}: {data}')
else:
print(f'{raw_file}: ERROR')I now have a file of extracted QR-codes. All alphanumeric, same length and nothing to stick out. Off to python again.
#!/usr/bin/env python3
from binascii import unhexlify
with open('./qr_codes_run2.txt', 'r') as file:
lines = file.readlines()
for line in lines:
line = line.strip('\n')
qr_code = line.split(' ')[1]
qr_code_unhex = unhexlify(qr_code)
decoded = qr_code_unhex.decode()
print(decoded)Running through the file and decoding all the strings as HEX, gave me a list of strings looking like base64 or similar. And here I literally was stuck for days (okay - maybe altogether 2-digit hours, but still); Nothing I tried would get me further. Decoding as base64, other base-variants, XOR's, Caesar-ciphers etc. At some point I even tried combining all the strings, but not knowing in which order to correctly do so, it was impossible to ensure a correct result. Then I looked into my earlier thought of the filenames being important somehow; I tried using it as cipher-keys, putting it in front and in the back of the strings - but nothing gave a result worth following.
One late night I finally acknowledged that I might needed some nudging, or at least confirmation that I was on the right track. A kind fellow CTF-practitioner on the JHDiscord-server acknowledged that I indeed was on the right track and that I was more or less done. It was brilliant to hear that the steps taken was correct and that I more or less was done. I was given the hint of "miscflag", and then immediately remembered that in the start of the CTF they told you, that all flags would be in the following formats:
GPSCTF{...}
StormCTF{...}
misc#{...}Had I already gotten the flag, but just overlooked it? Oh...
A quick python3 tinker3.py | tee strings.txt to save all the un-HEX'ed QR-codes in a file and then a simple grep misc strings.txt, and there it was. Hiding in plain sight; I literally didn't think of looking for the flag at every step, but tried hard to get to the "next step" even though no extra steps was to be found. That are indeed a lesson learned. But hey - my first CTF-event is now completed, and that at 7th place! Wow.
FLAG
miscflag3{6ea6d2a4e2d3a4bd5e275401aa086d86}