Day 15 in the Advent of Cyber 2023. Over the past few weeks, Best Festival Company employees have been receiving an excessive number of spam emails. These emails are trying to lure users into the trap of clicking on links and providing credentials. Spam emails are somehow ending up in the mailing box. It looks like the spam detector in place since before the merger has been disabled/damaged deliberately. Suspicion is on McGreedy, who is not so happy with the merger.
WARNING: Spoilers and challenge-answers are provided in the following writeup.
Official walk-through video is as well available at Youtube - Cybrites.
Day 15 - Jingle Bell SPAM: Machine Learning Saves the Day!
When implementing Machine Learning (ML) in processes, its important to know the "Machine Learning Pipeline". This builds upon yesterday's challenge where we walked through the high level understanding of what ML really is.
The first step in the pipeline is tremendously important - ML would not be possible without it. Data Collection. We need to collect data that we can train on, verify and test our model on. After collecting the data, next step is Data Preprocessing. This is as well a very important step, as we need to clean, normalize and standardize the data. Furthermore, we can transform, reduce, extract and engineer features on the data for enabling the ML model for better predictions, better understanding the data and more. We then need modeling. This is done by splitting our initial dataset into two sets for train and test, then applying our training model and finally evaluating the models performance.
The Challenge
Much like yesterday's challenge about Machine Learning and building a neural network, we are tasked today with utilizing a training model called "Naive Bayes Classifier" to predict spam emails.
Reading through the challenge-description and following along in the provided Jupyter-notebook, we can answer the first few questions. The main key step in an ML pipeline is data collection as we cannot train, test or otherwise work with ML without data. Having the data, we then need to process it and prepare it. One piece of this data preprocessing is about creating new features or modify existing ones to improve model performance and this one is named "Feature Engineering".
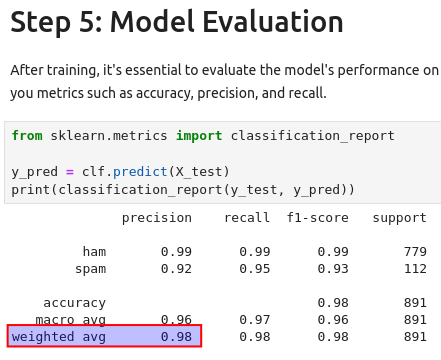
After training our model in Jupyter-notebook, we are asked what the weighted average for the precision is, which we can see in the model evaluation report.
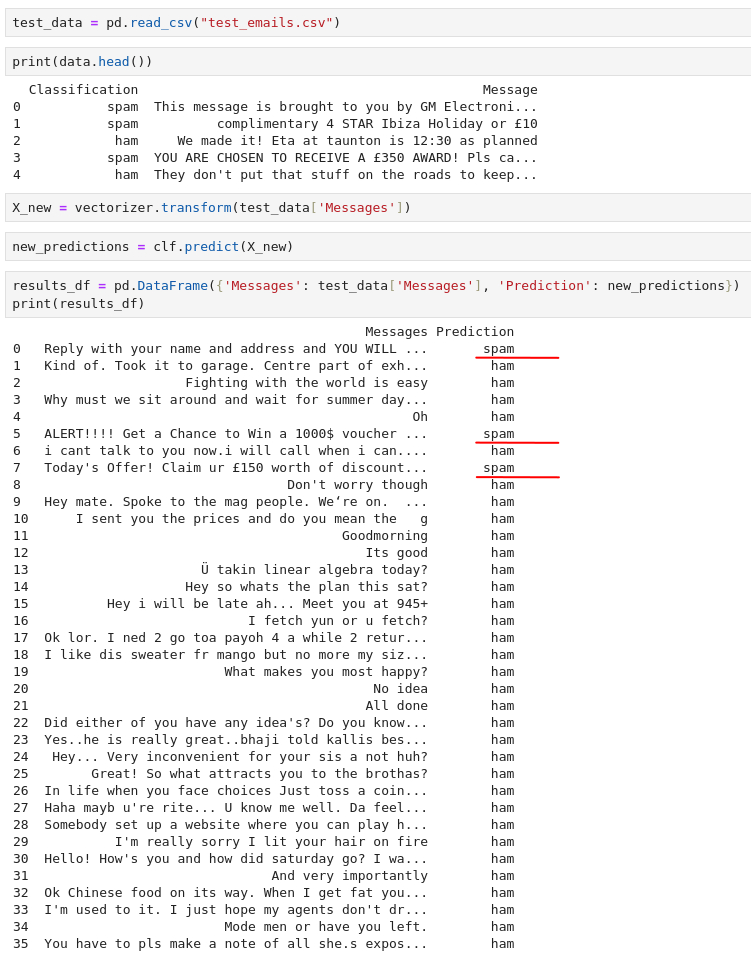
Next up, we are tasked to answer how many emails from the test-dataset has been predicted/marked as spam. Running our trained model on the test-dataset and we can see three predicted spam emails.
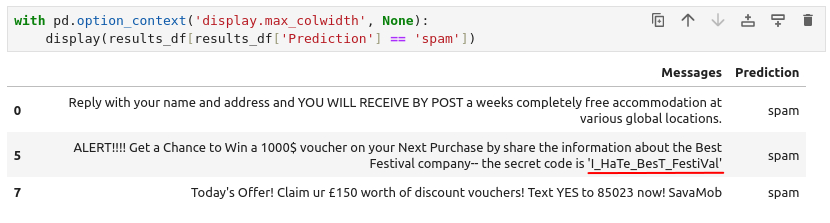
And lastly, we need to find a secret code from within one of those predicted spam-emails. We can use pandas to filter in the prediction-column and ensure to show the entirety of the messages.